The problem
Researchers spend an increasing amount of time trying to locate articles that relate to their topic of interest. Many biomedical researchers work on given part of a chromosome and have to switch between a genome browser and literature search engines very often. For these users, we have developed a targeted search engine, built into the UCSC Genome Browser.
Background: Spatial internet search engines
Map-based internet search engines like Yahoo/Bing/Google Maps rely on a process called "geocoding". In short, they search all pages of the internet for text that includes an address. They resolve them to GPS coordinates and place them on satellite maps of the earth. On a map, you can navigate webpages of businesses (e.g. restaurants) written in any language in your geographical area in a more intuitive way than with a keyword search.
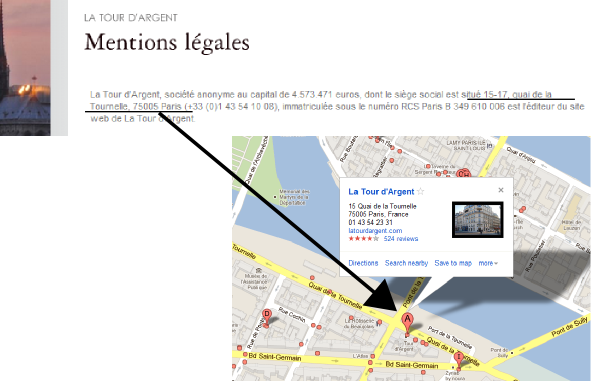
"Genocoding" scientific articles
Our project is running a software that searches for references to chromosomal locations in scientific articles. We show the results on the UCSC genome browser, which biomedical researchers use like a map to navigate the human chromosomes.
The following image on the homepage of our original project text2genome explains this with a DNA sequence:

Here, the software found a DNA sequence in a text and mapped it to a location on chromosome 5. Just like Yahoo/Google/Bing Maps, the software has found two words that represent an "address" (the DNA sequence). They are put at the right place on the genome browser's graphical map of a chromosome.
Just like street addresses, there are multiple ways to refer to a chromosomal location. DNA sequences are only one of them. Depending on the context and the experiment, authors use various other forms:
- Cytogenetic band names (like 17p13.1)
- Gene symbols (e.g. TP53)
- RefSeq Transcript identifiers (e.g. NM_001126113) or Ensembl ENST00000269305
- SNP Mutation identifiers, e.g. rs2909430
The five examples are all located on the same region on chromosome 17. They describe various ranges around the TP53 cancer gene. The last identifier, rs2909430, relates to only one single nucleotide of the human genome.
This means that in order to find the effects of a deletion on a chromosome, users have to go through search engines trying various identifiers, just like looking for an address with a normal Google Web Search.
When we have run our genocoding software, articles are linked on the genome browser like this:
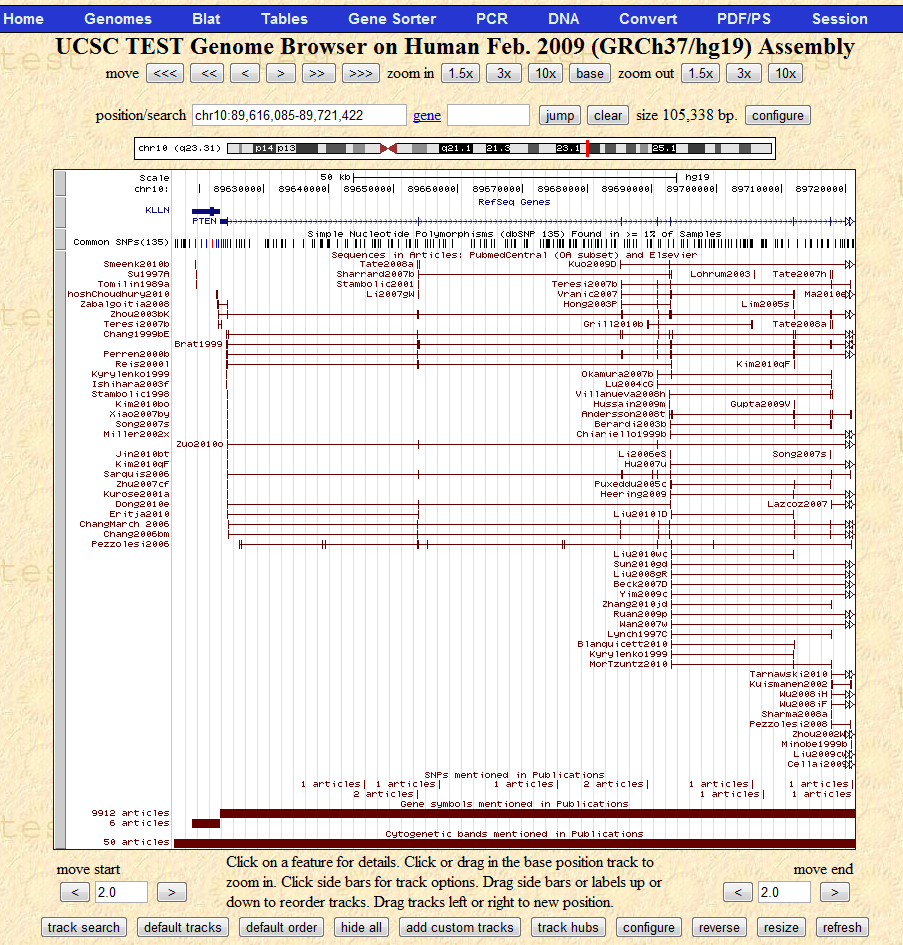
The first line show two genes, KKLN and PTEN. The second line highlights all mutations in databases in this area, most of them have never been mentioned in a paper. Underneath, you can see the results of the literature mapping.
Users can immediately see that most authors focussed on the right-hand part of the gene. In a separate line, you can see that the gene PTEN has been mentioned very often, in more than 9912 articles in the literature, while its immediate neighbor KKLN has been mentioned only six times.
Of more than 100 known mutations in this genomic region, only nine have been mentioned. Users can now click on all these highlighted features and get redirected to the title, snippet and the authors of the article, with a direct link to the fulltext article on the publisher's webpage.
Here is an example click on one of the mutations:
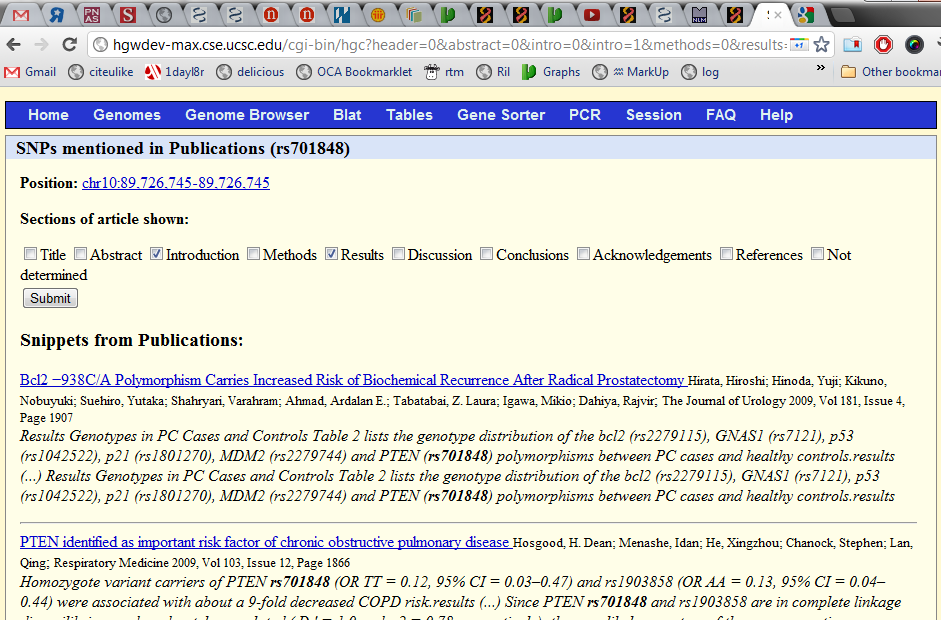
Highlighted is a snippet around the mention, similar to what Google Scholar shows:

Note that to find this hit with a search engine like Google Scholar or Bing Academic alone, one would have to go through all the thousands of articles that mentioned the gene PTEN or alternatively search for all mutation identifiers in this genomic region of PTEN, of which there are at least 100.
What our software does
- It requests Medline entries for a journal, downloads a PDF from the publishers' server (not more than 3 per minute)
- It converts the PDF (or Microsoft Office, XML, etc) to text
- The text is searched for these genomic identifiers:
- Species names from NCBI Taxonomy
- Official HGNC Gene symbols from genenames.org
- Cytogenetic Bands (simplified version of the ISCN standard)
- SNP Mutation identifiers (currently only dbSNP identifiers, planned: synonyms)
- (planned: STS marker names from NCBI UniSTS)
- DNA and protein sequences (details see below)
Summary
Our software links articles from the genomic locations that they discuss, in a more comprehensive way than normal keyword searches. We believe this provides benefits to the biomedical research community and to the publishing industry alike.